Datasets
There are many datasets used in experiments with OOD methods. Finding, downloading and writing code for reading these datasets can be tedious.
This package provides access to some of the most used datasets in the OOD literature. Most of these implementations support auto-downloading.
Image
Classification
Contains datasets often used in anomaly Detection, where the entire input is labels as either ID or OOD.
Textures

TinyImageNetCrop
TinyImageNetResize
LSUNCrop
LSUNResize
TinyImageNet
- class pytorch_ood.dataset.img.TinyImageNet(root, subset='train', download=False, transform=None, target_transform=None)[source]
Small Version of the ImageNet with images of size \(64 \times 64\) from 200 classes used by Stanford. Each class has 500 images for training.

This dataset is often used for training, but not included in Torchvision.
- See Website:
- Para subset:
can be one of
train,valandtest
Places365
- class pytorch_ood.dataset.img.Places365(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
Images sourced from the Places365 dataset used as OOD data, usually for CIFAR 10 and 100. All labels are -1 by default.
Dataset set contains 36500 images.
- See Website:

80M TinyImages
- class pytorch_ood.dataset.img.TinyImages(datafile, cifar_index_file, transform=None, target_transform=None, exclude_cifar=True)[source]
The TinyImages dataset is often used as auxiliary OOD training data. While it has been removed from the website, downloadable versions can be found on the internet.
- See Website:
- See Mirror:
Warning
The use of this dataset is discouraged by the authors. If you are interested in the underlying reasons, see Large image datasets: A pyrrhic win for computer vision?
300K Random Images
ImageNet-A
ImageNet-O
ImageNet-R
- class pytorch_ood.dataset.img.ImageNetR(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
The ImageNet-R(endition) from the paper The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization contains art, cartoons, deviantart, graffiti, embroidery, graphics, origami, paintings, patterns, plastic objects, plush objects, sculptures, sketches, tattoos, toys, and video game renditions of ImageNet classes.
ImageNet-V2
- class pytorch_ood.dataset.img.ImageNetV2(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
A new test set for ImageNet, introduced in Do ImageNet Classifiers Generalize to ImageNet?. While it contains no OOD data, it is utilized for evaluating OOD detection methods.
- See Paper:
The test set consists of 10000 images across 1000 classes, with 10 images per class.
ImageNet-ES
- class pytorch_ood.dataset.img.ImageNetES(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
A new test set for ImageNet as event-stream (ES) version, introduced in ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks. While it contains no OOD data, it is utilized for evaluating OOD detection methods.
The provided data here is similar to that in the OpenOOD benchmark, making it only a subset of the original dataset.
- See Paper:
The test set consists of 64000 images across 200 different classes.
MNIST-C
- class pytorch_ood.dataset.img.MNISTC(root: str, subset: str, split: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
MNIST-C is MNIST with corruptions for benchmarking OOD methods.
Split can be one of
train,testandleftovers.Subsets can be one of
all,brightness,canny_edges,dotted_line,fog,glass_blur,identity,impulse_noise,motion_blur,rotate,scale,shear,shot_noise,spatter,stripe,translateandzigzag.
CIFAR10-C
- class pytorch_ood.dataset.img.CIFAR10C(root: str, subset: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
Corrupted version of the CIFAR10 from the paper Benchmarking Neural Network Robustness to Common Corruptions and Perturbations.
CIFAR100-C
- class pytorch_ood.dataset.img.CIFAR100C(root: str, subset: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
Corrupted version of the CIFAR100 from the paper Benchmarking Neural Network Robustness to Common Corruptions and Perturbations.
CIFAR100-GAN
- class pytorch_ood.dataset.img.CIFAR100GAN(root, transform=None, target_transform=None, download=False, sigma=50.0)[source]
Images sampled from low likelihood regions of a BigGAN trained on CIFAR 100 from the paper On Outlier Exposure with Generative Models.
Can be used as auxiliary outliers, e.g. for
OutlierExposureor any of the supervised training objectives in general.Default sample \(\sigma\) is 50.0. Contains 50,000 samples. Label is -1 by default.

- See Website:
- See Paper:
- Parameters:
root – where to store the dataset
transform – transform to apply to the data
target_transform – transform to apply to the target
download – whether to download the dataset if it is not found in root
sigma – sample \(\sigma\) used to generate dataset. Can be
50.0or2.0.
ImageNet-C
- class pytorch_ood.dataset.img.ImageNetC(root: str, subset: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
Corrupted version of the ImageNet from the paper Benchmarking Neural Network Robustness to Common Corruptions and Perturbations.
It contains several subsets:
noise(21GB): gaussian_noise, shot_noise, and impulse_noise.blur(7GB): defocus_blur, glass_blur, motion_blur, and zoom_blur.weather(12GB): frost, snow, fog, and brightness.digital(7GB): contrast, elastic_transform, pixelate, and jpeg_compression.extra(15GB): speckle_noise, spatter, gaussian_blur, and saturate.
- See Paper:
OpenImages-O
- class pytorch_ood.dataset.img.OpenImagesO(root: str, subset='test', transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
Images sourced from the OpenImages dataset used as OOD data for ImageNet, as provided in OpenOOD: Benchmarking Generalized Out-of-Distribution Detection. All labels are -1 by default.
- See Website:
The test set contains 15869 , the validation set 1763 images.
- Parameters:
subset – can be either
valortest
iNaturalist
- class pytorch_ood.dataset.img.iNaturalist(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
Subset of the iNaturalist dataset used as OOD data for ImageNet, proposed in MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space.
All labels are -1 by default.
- See Paper:
- See Paper:
SSBHard
- class pytorch_ood.dataset.img.SSBHard(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
The SSB-hard is the hard split of the Semantic Shift Benchmark (SSB), introduced in Open-set recognition: A good closed-set classifier is all you need. This dataset only provides OOD data and is used for open-set recognition for models trained on ImageNet1K.
- See Paper:
The test set consists of 49000 images.
Chars74k

Fractals
Fooling Images

NINCO
- class pytorch_ood.dataset.img.NINCO(root: str, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
NINCO dataset from the paper In or Out? Fixing ImageNet Out-of-Distribution Detection Evaluation. Contains 5879 OOD images from 64 classes. The images have been manually verified as OOD.
Labels are -1 by default.
Note
Calculating metrics over the entire dataset will result in slightly different results compared to the original publication, as they calculate metrics over each class individually and report the mean.
Feature Visualizations
Gaussian Noise
- class pytorch_ood.dataset.img.GaussianNoise(length: int, size=(224, 224, 3), transform=None, target_transform=None, loc: int = 128, scale: int = 128, seed: int | None = None)[source]
Dataset with samples drawn from a normal distribution.
- Parameters:
length – number of samples in the dataset
size – shape of the generated noise samples
transform – transformation to apply to images
target_transform – transformation to apply to labels
loc – mean \(\mu\) of the gaussian
scale – scaling factor \(\sigma^2\) of the gaussian
seed – random seed
Uniform Noise
- class pytorch_ood.dataset.img.UniformNoise(length: int, size=(224, 224, 3), transform=None, target_transform=None, seed: int | None = None)[source]
Dataset with samples drawn from uniform distribution.
- Parameters:
length – number of samples in the dataset
size – shape of the generated noise samples
transform – transformation to apply to images
target_transform – transformation to apply to labels
seed – random seed
Segmentation
StreetHazards
- class pytorch_ood.dataset.img.StreetHazards(root: str, subset: str, transform: Callable[[Tuple], Tuple] | None = None, download: bool = False)[source]
Benchmark Dataset for Anomaly Segmentation.
From the paper Scaling Out-of-Distribution Detection for Real-World Settings

- See Paper:
- See Website:
- Parameters:
root – root path for dataset
subset – one of
train,test,validationtransform – transformations to apply to images and masks, will get tuple as argument
download – if dataset should be downloaded automatically
- classes: List[str] = ['unlabeled', 'building', 'fence', 'other', 'pedestrian', 'pole', 'road line', 'road', 'sidewalk', 'vegetation', 'car', 'wall', 'traffic sign']
class index to name mapping
FishyScapes
- class pytorch_ood.dataset.img.FishyScapes(root, cs_root, version='3.0.0', download: bool = False, transforms=None)[source]
The FishyScapes dataset contains images from the CityScapes dataset blended with unknown objects scraped from the web. You additionally have to manually download the CityScapes validation dataset (left, 8 bit).
The dataset contains annotations for a void-class that should be ignored during evaluation.
There are currently three versions:
1.0.0- not blended2.0.0- slightly blended3.0.0- well blended

- See Paper:
- See Website:
- See Implementation:
- Parameters:
root – dataset root
cs_root – directory with cityscapes validation images
version – can be one of
1.0.0,2.0.0,3.0.0download – whether to download the dataset
transforms – transformations to apply to image and target mask
- VOID_LABEL = 1
void label, should be ignored during score calculation
LostAndFound
- class pytorch_ood.dataset.img.LostAndFound(root, download=False, transforms=None)[source]
The LostAndFound dataset contains images from driving scenarios with real world anomalies. It can be used with models trained on CityScapes.
The dataset contains annotations for a void-class that should be ignored during evaluation. The labels are provided by FishyScapes.

Warning
The image with index 79 does not contain any outlier pixels.
- Parameters:
root – where datasets are stored
download – set true to automatically download datasets
transforms – transforms applied to image and mask
- VOID_LABEL = 1
void label, should be ignored during score calculation
RoadAnomaly

SegmentMeIfYouCan
- class pytorch_ood.dataset.img.SegmentMeIfYouCan(root: str, subset: str, transform: Callable[[Tuple], Tuple] | None = None, download: bool = False)[source]
Benchmark Dataset for Anomaly Segmentation.
From the paper SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation. Contains two subsets: RoadAnomaly21 and RoadObstacle21
Note
Similar to Paper Segment Every Out-of-Distribution Object (ArXiv, Github) for
RoadAnomaly21only 10 and forRoadObstacle21only 30 images are available.- See Paper:
- See Website:
- Parameters:
root – root path for dataset
subset – one of
RoadAnomaly21,RoadObstacle21transform – transformations to apply to images and masks, will get tuple as argument
download – if dataset should be downloaded automatically
- VOID_LABEL = 1
void label, should be ignored during score calculation
MVTech-AD
- class pytorch_ood.dataset.img.MVTechAD(root: str, split: str, subset: str | None = None, transform: Callable | None = None, target_transform: Callable | None = None, download: bool = False)[source]
MVTec AD is a dataset for benchmarking anomaly detection methods with a focus on industrial inspection. The dataset provides segmentation masks for anomalies.

- See Paper:
https://link.springer.com/content/pdf/10.1007/s11263-020-01400-4.pdf
- See Download:
Split must be one of
trainortest.Subset classes can be one of
bottle,cable,capsule,carpet,grid,hazelnut,leather,metal_nut,pill,screw,tile,toothbrush,transistor,woodandzipper.- Parameters:
root – root directory
split – split directory
subset – subset class to use
transform – transformations to apply to image
target_transform – transformation to apply to target masks
download – set to true to automatically download the dataset
Object Detection
SuMNIST
- class pytorch_ood.dataset.img.SuMNIST(root, train=True, transforms=None, download=False)[source]
The SuMNIST dataset comprises images with a size of \(56 \times 56\), each containing 4 numbers from the MNIST dataset. In the training dataset, there are 60,000 normal instances where the numbers in the image sum to 20. However, the test set with 10,000 images, there are 8,500 normal instances and 1,500 anomalous instances for which the numbers do not sum to 20. The challenge is to detect these anomalies.
Returns a tuple with
(img, dict)where dict contains bounding boxes, labels, etc.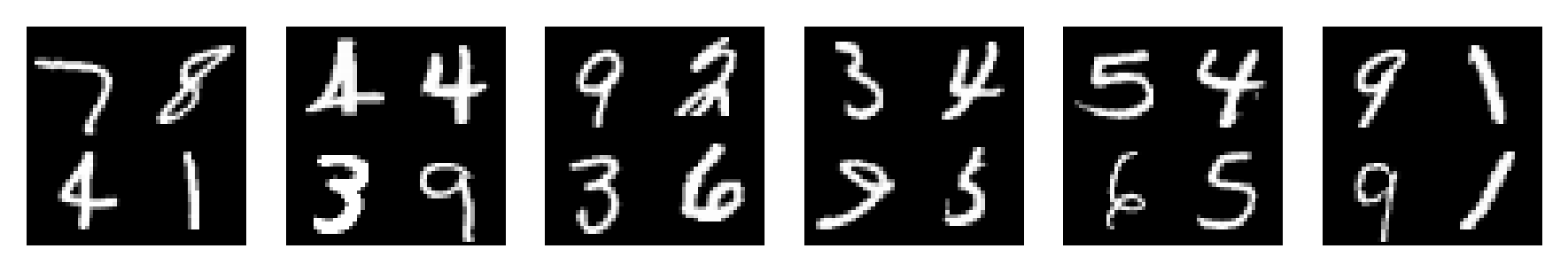
- Parameters:
root – where to store dataset
train – set to False to use test set
transforms – callable to apply to image and target dictionary
download – set to True to download automatically
Text
Newsgroups
Reuters 8
Reuters 52
Multi30k
WMT16 Sentences
WikiText 2
- class pytorch_ood.dataset.txt.WikiText2(root, split, transform=None, target_transform=None, download=True)[source]
Contains collection of over 100 million tokens extracted from the set of verified Good and Featured articles on Wikipedia.
Usually used os OOD (training) data, for example, for
Outlier Exposure. Labels are -1 by default.Split can be one of
train,testandval.- See Paper:
WikiText 103
- class pytorch_ood.dataset.txt.WikiText103(root, split, transform=None, target_transform=None, download=True)[source]
Contains collection of over 100 million tokens extracted from the set of verified Good and Featured articles on Wikipedia.
Usually used os OOD (training) data, for example, for
Outlier Exposure. Labels are -1 by default.Split can be one of
train,testandval.- See Paper:
Audio
Free Spoken Digit Dataset
- class pytorch_ood.dataset.audio.FSDD(root, transform=None, target_transform=None, download=True)[source]
Free Spoken Digit Dataset, a simple audio/speech dataset consisting of recordings of spoken digits in wav format at 8kHz.
- See Website:
- Parameters:
root – root folder for the dataset
transform – transform that will be applied to the instance
target_transform – transform that will be applied to the label
download – set true if you want to download dataset automatically
Video
Note
There are, to our knowledge, no video datasets for OOD detection available. If you are aware of any, please, let us know.
Open Set Simulations
Open Set Simulations are frequently used to evaluate Open Set Recognition models. The idea is to split a dataset with labels into subsets of known (IN) and unknown (OOD) classes. These subsets are then used to train the model on the known classes and evaluated on known and unknown classes.
A formal description can be found in this paper.
- class pytorch_ood.dataset.ossim.DynamicOSS(dataset, train_size: float = 0.7, val_size: float = 0.2, test_size: float = 0.1, kuc: int = 0, uuc_val: int = 2, uuc_test: int = 2, seed=None)[source]
Dynamically samples an Open Set Simulation from a dataset.
- Parameters:
train_size – ratio of test samples
val_size – ratio of validation samples
test_size – ratio of test samples
kuc – number of out-of-distribution classes in training set (known unknowns)
uuc_val – number of out-of-distribution classes in validation set (unknown unknowns)
uuc_test – number of out-of-distribution classes in test set (unknown unknowns + test)
seed – seed to use for splits
- property kkc: Set
Known Known Classes
- property kuc: Set
Known Unknown Classes
- test_dataset(in_dist: bool = True, out_dist: bool = True) Subset[source]
- Parameters:
in_dist – include ID data
out_dist – include OOD data
- Returns:
- train_dataset(in_dist: bool = True, out_dist: bool = True) Subset[source]
- Parameters:
in_dist – include ID data
out_dist – include OOD data
- Returns:
- property unique_targets
List of all existing classes
- property uuc: Set
Unknown Unknown Classes