Benchmarks
Benchmark objects aim to provide a higher level interface to recreate the OOD detection benchmarks used in the literature.
API
Each benchmark implements a common interface.
Note
This is currently a draft and likely subject to change in the future.
benchmark = Benchmark(root)
detector = Detector(model)
detector.fit(benchmark.train_set())
results1 = benchmark.evaluate(detector1)
results2 = benchmark.evaluate(detector2)
Several detectors can also be evaluated together. Benchmark caching can reuse intermediate logits or pooled features when evaluating multiple compatible detectors:
results = benchmark.evaluate(
[detector1, detector2],
cache=True,
cache_dir="cache/",
cache_key="wrn-cifar10-v1",
)
When possible, benchmarks reuse cached logits or pooled features for
LogitsDetector and FeaturesDetector instances. With cache=True,
those cached representations are kept on the benchmark object and can be
reused across later evaluate(...) calls. With cache_dir=..., they
can also be written to disk.
Warning
File-backed cache reuse is keyed only by the user-supplied cache_key
and lightweight metadata. Users are responsible for changing the key when
the model, weights, transforms, or benchmark configuration change.
- class pytorch_ood.benchmark.Benchmark[source]
Base class for Benchmarks
- evaluate(detector: Detector, loader_kwargs: Dict | None = None, device: str = 'cpu', cache: bool = False, cache_dir: str | None = None, cache_key: str | None = None) List[Dict][source]
- evaluate(detector: Sequence[Detector], loader_kwargs: Dict | None = None, device: str = 'cpu', cache: bool = False, cache_dir: str | None = None, cache_key: str | None = None) List[Dict]
Evaluate one detector or a list of detectors on all benchmark datasets.
When several logits detectors or pooled-feature detectors are evaluated together, this method can reuse cached intermediate representations instead of recomputing model outputs for every detector. If
cache=True, those representations are also kept on the benchmark instance and reused across laterevaluate(...)calls. Ifcache_diris given, cached tensors are additionally persisted to disk.Disk-backed cache reuse is keyed only by user-provided
cache_keyand lightweight metadata, so cache correctness is the caller’s responsibility.- Parameters:
detector – detector instance or a sequence of detectors
loader_kwargs – keyword arguments forwarded to the data loader
device – device to move inputs and detectors to
cache – keep cached representations on the benchmark instance
cache_dir – optional directory for file-backed caches
cache_key – user-supplied cache key used for disk cache reuse
- Returns:
benchmark results. For multiple detectors, each result includes a
Detectorfield with the detector class name.
Image
Examples can be found here
CIFAR 10
ODIN Benchmark
- class pytorch_ood.benchmark.CIFAR10_ODIN(root, transform)[source]
Replicates the OOD detection benchmark from the ODIN paper for CIFAR 10.
- See Paper:
Outlier datasets are
TinyImageNetCrop
TinyImageNetResize
LSUNResize
LSUNCrop
Uniform
Gaussian
- Parameters:
root – where to store datasets
transform – transform to apply to images
- ood_names: List[str]
OOD Dataset names
OpenOOD Benchmark
- class pytorch_ood.benchmark.CIFAR10_OpenOOD(root, transform)[source]
Replicates the CIFAR-10 benchmark proposed in OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection.
- See Paper:
Near-OOD datasets:
CIFAR-100
TinyImageNet
Far-OOD datasets:
MNIST
SVHN
Textures
Places365
- Parameters:
root – where to store datasets
transform – transform to apply to images
- ood_names: List[str]
OOD Dataset names
CIFAR 100
ODIN Benchmark
- class pytorch_ood.benchmark.CIFAR100_ODIN(root, transform)[source]
Replicates the OOD detection benchmark from the ODIN paper for CIFAR 100.
- See Paper:
Outlier datasets are
TinyImageNetCrop
TinyImageNetResize
LSUNResize
LSUNCrop
Uniform
Gaussian
- Parameters:
root – where to store datasets
transform – transform to apply to images
- ood_names: List[str]
OOD Dataset names
OpenOOD Benchmark
- class pytorch_ood.benchmark.CIFAR100_OpenOOD(root, transform)[source]
Aims to replicate the benchmark proposed in OpenOOD: Benchmarking Generalized Out-of-Distribution Detection.
- See Paper:
Outlier datasets are
CIFAR10
TinyImageNet
MNIST
FashionMNIST
Textures
Places365
Warning
This currently does not reproduce the benchmark accurately, as it does not exclude images with overlap with CIFAR100.
- Parameters:
root – where to store datasets
transform – transform to apply to images
- ood_names: List[str]
OOD Dataset names
ImageNet
OpenOOD Benchmark
- class pytorch_ood.benchmark.ImageNet_OpenOOD(root, image_net_root, transform)[source]
Replicates the ImageNet benchmark proposed in OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection.
- See Paper:
Near-OOD datasets:
SSB-Hard
NINCO
Far-OOD datasets:
iNaturalist
Textures
OpenImage-O
- Parameters:
root – where to store datasets
image_net_root – root for the ImageNet dataset
transform – transform to apply to images
- ood_names: List[str]
OOD Dataset names
Medical Imaging
OpenMIBOOD Benchmarks
The benchmarks proposed in OpenMIBOOD: Open Medical Imaging Benchmarks for Out-Of-Distribution Detection (arXiv:2503.16247, CVPR 2025). Each benchmark uses a 4-way split (ID, covariate-shifted ID, near-OOD, far-OOD). Data must be prepared first following the OpenMIBOOD setup guide.
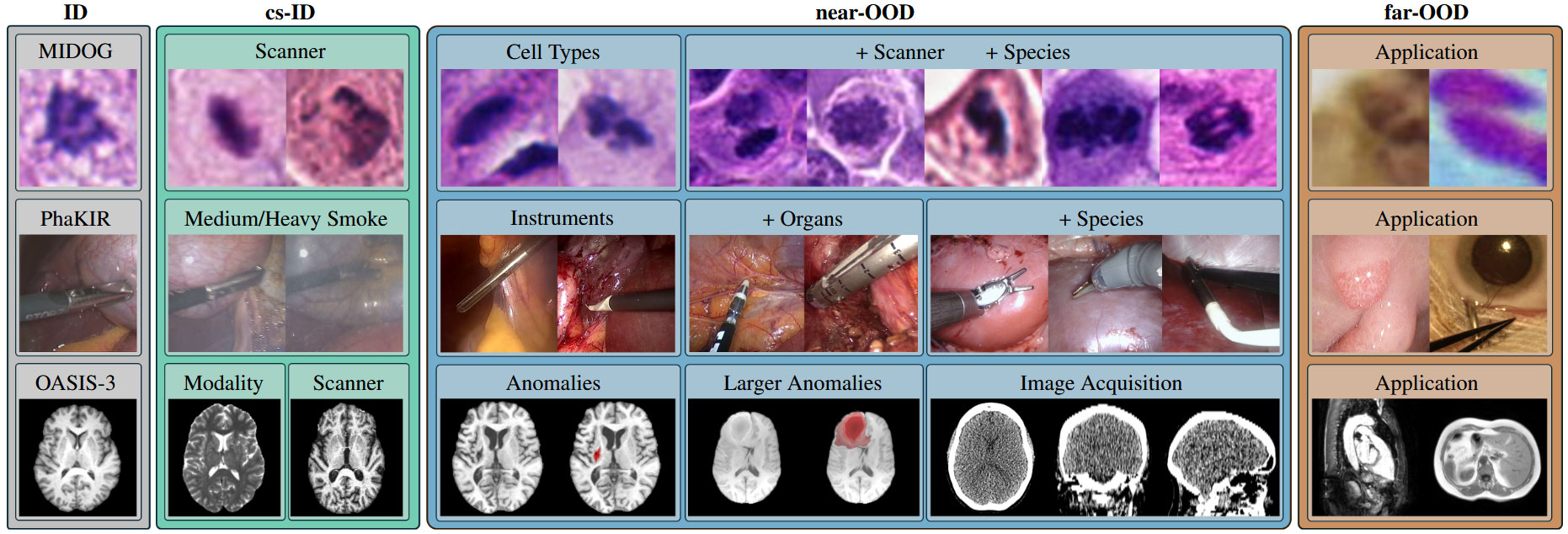
MIDOG (microscopy / mitosis)
- class pytorch_ood.benchmark.MIDOG_OpenMIBOOD(root: str, transform: Callable, loader: Callable[[str], Any] | None = None, download: bool = True)[source]
Replicates the MIDOG benchmark proposed in OpenMIBOOD: Open Medical Imaging Benchmarks for Out-Of-Distribution Detection. Images are 50x50 TIFF patches; the in-distribution task is 3-class mitosis classification on Domain 1a.
Requires data prepared following the OpenMIBOOD setup guide.
rootshould point at the directory whose subfolders match the bundled imglist paths (e.g.1a/017/017_342_0.tiff).Covariate-shifted ID datasets:
midog_csid_1b— Domain 1b (different scanner, same task)midog_csid_1c— Domain 1c (different scanner, same task)
Near-OOD datasets (other scanner/staining domains):
midog_2,midog_3,midog_4,midog_5,midog_6a,midog_6b,midog_7
Far-OOD datasets (different cytology):
midog_ccagt— cervical cells (CCAgT)midog_fnac2019— fine-needle aspirate cytology (FNAC 2019)
- See Paper:
- See Setup:
- Parameters:
root – directory containing the prepared OpenMIBOOD data for this benchmark
transform – transform applied to each loaded image (after
ToRGB)loader – callable mapping a file path to an image; defaults to
PIL.Image.open(). Required for benchmarks whose image format is not handled by PIL (e.g. NIfTI).download – if
True, download missing imglist files toroot/imglists/<bench>/. IfFalse, raise an error if any required file is missing. Defaults toTrue.
- cs_id_names: ClassVar[List[str]] = ['midog_csid_1b', 'midog_csid_1c']
covariate-shifted ID dataset names
- far_ood_names: ClassVar[List[str]] = ['midog_ccagt', 'midog_fnac2019']
far-OOD dataset names
- near_ood_names: ClassVar[List[str]] = ['midog_2', 'midog_3', 'midog_4', 'midog_5', 'midog_6a', 'midog_6b', 'midog_7']
near-OOD dataset names
PhaKIR (surgical video)
- class pytorch_ood.benchmark.PhaKIR_OpenMIBOOD(root: str, transform: Callable, loader: Callable[[str], Any] | None = None, download: bool = True)[source]
Replicates the PhaKIR benchmark proposed in OpenMIBOOD: Open Medical Imaging Benchmarks for Out-Of-Distribution Detection. Images are PNG video frames; the in-distribution task is 7-class surgical-phase classification on PhaKIR videos 02-04 and 07 (Video 01 is held out for testing).
Requires data prepared following the OpenMIBOOD setup guide.
rootshould point at the directory whose subfolders match the bundled imglist paths (e.g.Video_02/Video_02_Frames/frame_0_19_0.png).Covariate-shifted ID datasets:
phakir_medium_smoke— same procedure with medium smoke artifactsphakir_heavy_smoke— same procedure with heavy smoke artifacts
Near-OOD datasets (other laparoscopic surgery videos):
phakir_cholec— Cholec80phakir_endovis2015— EndoVis 2015phakir_endovis2018— EndoVis 2018
Far-OOD datasets (different surgical/clinical domains):
phakir_kvasir— Kvasir-SEG (gastrointestinal endoscopy)phakir_cataracts— CATARACTS (ophthalmic surgery)
- See Paper:
- See Setup:
- Parameters:
root – directory containing the prepared OpenMIBOOD data for this benchmark
transform – transform applied to each loaded image (after
ToRGB)loader – callable mapping a file path to an image; defaults to
PIL.Image.open(). Required for benchmarks whose image format is not handled by PIL (e.g. NIfTI).download – if
True, download missing imglist files toroot/imglists/<bench>/. IfFalse, raise an error if any required file is missing. Defaults toTrue.
- cs_id_names: ClassVar[List[str]] = ['phakir_medium_smoke', 'phakir_heavy_smoke']
covariate-shifted ID dataset names
- far_ood_names: ClassVar[List[str]] = ['phakir_kvasir', 'phakir_cataracts']
far-OOD dataset names
- near_ood_names: ClassVar[List[str]] = ['phakir_cholec', 'phakir_endovis2015', 'phakir_endovis2018']
near-OOD dataset names
OASIS-3 (brain MRI)
- class pytorch_ood.benchmark.OASIS3_OpenMIBOOD(root: str, transform: Callable, loader: Callable[[str], Any] | None = None, download: bool = True)[source]
Replicates the OASIS-3 benchmark proposed in OpenMIBOOD: Open Medical Imaging Benchmarks for Out-Of-Distribution Detection. Images are NIfTI (
.nii.gz) 3D volumes (skull-stripped, resampled); the in-distribution task is 2-class classification on T1w scans.Requires data prepared following the OpenMIBOOD setup guide.
rootshould point at the directory whose subfolders match the bundled imglist paths (e.g.OASIS3/OAS30704/.../sub-OAS30704_..._T1w_resampled_skull_stripped.nii.gz).Note
NIfTI files are not handled by
PIL.Image.open. You must supply aloadercallable that maps a file path to an image (typically a 2D slice extracted from the 3D volume). For example:import nibabel as nib from PIL import Image def load_central_slice(path): vol = nib.load(path).get_fdata() sl = vol[:, :, vol.shape[2] // 2] sl = (255 * (sl - sl.min()) / max(sl.ptp(), 1e-8)).astype("uint8") return Image.fromarray(sl) bench = OASIS3_OpenMIBOOD(root, transform=t, loader=load_central_slice)
Covariate-shifted ID datasets:
oasis3_scanner— Siemens MAGNETOM Vision scanner T1woasis3_t2w— T2-weighted modality
Near-OOD datasets (other brain MRI):
oasis3_atlas— ATLAS R2.0 (stroke lesions)oasis3_brats— BraTS 2023 gliomaoasis3_ct— OASIS-3 CT
Far-OOD datasets (other body regions):
oasis3_heart— MSD Task02 Heartoasis3_chaos_inPhase— CHAOS abdominal MRI (in-phase)
- See Paper:
- See Setup:
- Parameters:
root – directory containing the prepared OpenMIBOOD data for this benchmark
transform – transform applied to each loaded image (after
ToRGB)loader – callable mapping a file path to an image; defaults to
PIL.Image.open(). Required for benchmarks whose image format is not handled by PIL (e.g. NIfTI).download – if
True, download missing imglist files toroot/imglists/<bench>/. IfFalse, raise an error if any required file is missing. Defaults toTrue.
- cs_id_names: ClassVar[List[str]] = ['oasis3_scanner', 'oasis3_t2w']
covariate-shifted ID dataset names
- far_ood_names: ClassVar[List[str]] = ['oasis3_heart', 'oasis3_chaos_inPhase']
far-OOD dataset names
- near_ood_names: ClassVar[List[str]] = ['oasis3_atlas', 'oasis3_brats', 'oasis3_ct']
near-OOD dataset names